
Robots Txt File Editing to Block Dynamic URL's
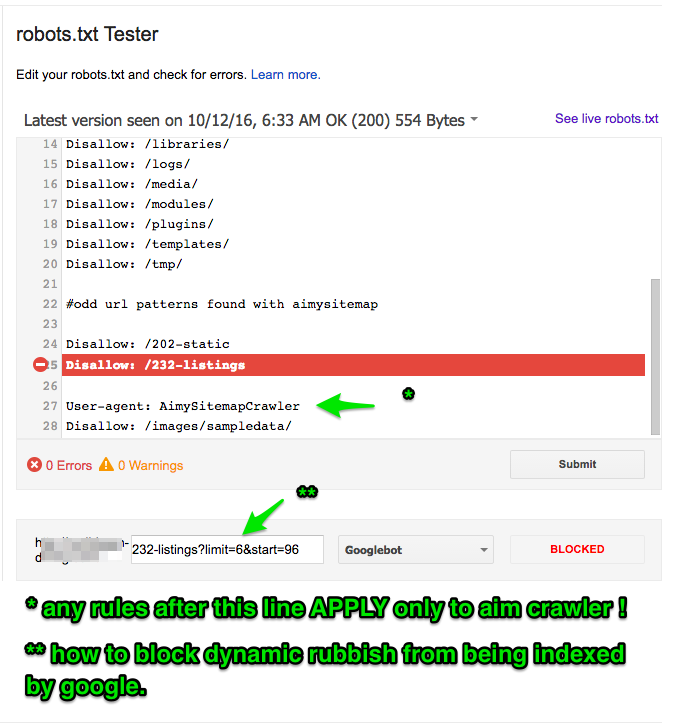
I am taking a closer look at Robots.txt today and found the need to block some dynamic urls that a site crawler found. This is a GREAT SEO TIP!
Google should be given as much information about what your website is about. Also try to make sure what google get is what you want them to get. I am particularly bothered by url's like in the image above that show nothing new and therefore are showing duplicate content. All your website content needs to be fresh and handwritten by you. You know your business best. But your website with these url's shows duplication. Using the robots.txt file found usually in the site root of the webspace is a tool for you to help google.
I found some people saying that you can use regular expressions I did not find them to be working. Use the webmasters console to check the robots text file and check pages you also want to allow to work.
If you want to block urls that is dynamic like
site.com/blogs/static-1
site.com/blogs/static-2
site.com/blogs/static-3
Try to find the pattern and use this to block them - the trailing slash is key (don't use it)
Disallow: /static-
I hope that you found this short blog post useful I will file it under SEO as that's generally why you would be interested to get this part of the website correct.
About the author
Related Posts
Comments 1

This is a helpful url on robots.txt editing from the amazing STACKOVERFLOW website.
http://stackoverflow.com/questions/1495363/how-to-disallow-all-dynamic-urls-robots-txt
By accepting you will be accessing a service provided by a third-party external to https://cambs.eu/